
2024年华南师范大学“新师范”融合创新夏令营。
本学习资料由华南师范大学钟柏昌教授团队原创,未经许可不得以任何形式转载,仅供夏令营学习。
1. 人工智能模型训练的流程与简化
在中小学人工智能教育的实施过程中,让学生体验模型训练是引导学生逐步探索人工智能内在原理的必经之路。但模型训练的门槛较高,想让中小学学生体验模型训练,必须选择合适的工具简化模型训练的流程,使得学生能在低代码、甚至无代码的环境下完成模型训练。
本章将主要介绍浦育人工智能教育平台的部分功能以及其他具有使用价值的工具和平台。请大家根据本章内容,完成体验性活动,思考如何应用合适的工具实现中小学人工智能的进阶式教学。
2. 浦育人工智能平台使用
浦育人工智能平台(https://www.openinnolab.org.cn/)是专门面向青少年的AI开放平台,其致力于向教师与学生提供易用的人工智能学习创作工具,本章将分别介绍该平台AI体验部分的图像分类功能,以及如何使用该平台体验经典的MNIST手写体数字识别。
2.1 AI体验:图像分类

点击AI体验>图像分类>开始体验,即可进入如图所示界面。

界面整体可分为三个部分,从左往右依次为数据集制作、模型训练、模型评估。该平台的主要操作流程为:使用摄像头拍摄图片或直接上传本地图片,制作图像分类的数据集,准备好后点击“开始训练”并等待模型训练完成,最后通过调取摄像头,可以对模型效果进行简单评估,并下载保存训练的模型。
该功能模块将模型训练等操作都做了最大程度的简化,让学生在使用该工具时可以聚焦于数据集的制作上,降低学生的学习负荷。
数据集是一组数据,通常以结构化的形式组织,可以是表格、图像、文本等,在图像分类中以图像的形式展现。数据集在AI和机器学习中用于训练和测试模型。它是模型学习和评估的重要基础。

图像分类所用到的数据集相对较为简单,每个数据集都由图像(Images)和标签(Labels)组成。图中的“分类1”就是标签,它标记了该分类下的图片都为同一类图像。图像分类的模型就是通过对数据集的学习,提取每一类图像的特征,以实现当获得一张新图像时,能自动给新图像选择正确的标签。
注意:在后文的3.2中介绍了图片爬取工具,制作数据集时可先学习该部分内容,用图片爬取工具批量获取图片,完成数据集制作。
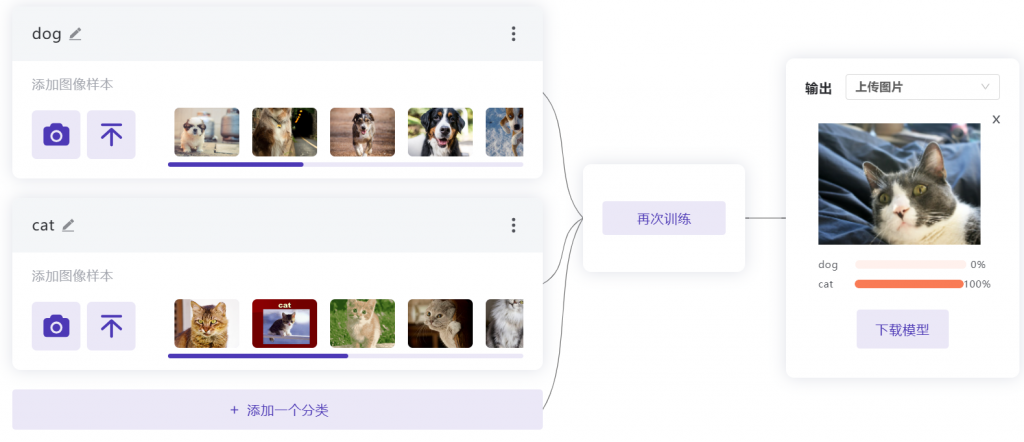
图示案例为对猫狗分类模型的训练,完成模型训练后可选择对上传的图片进行图像分类。
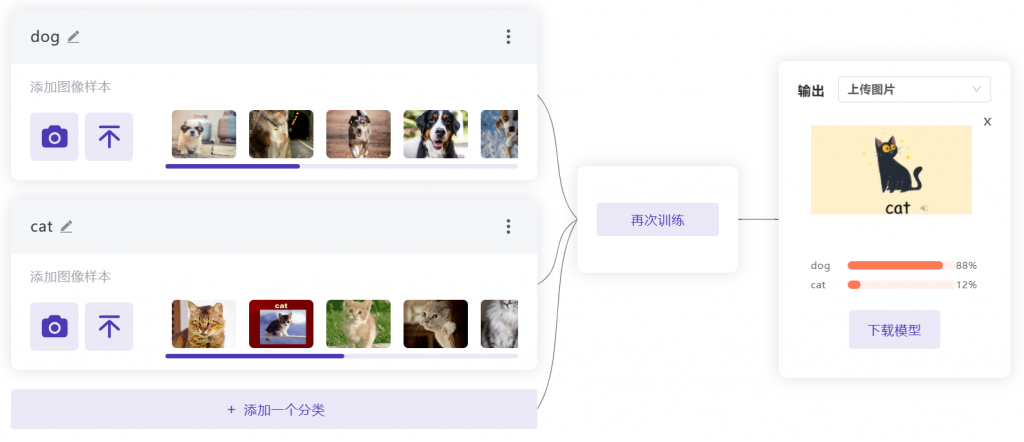
在体验该功能时,需要注意模型的效果与数据集的质量、数量息息相关,数据集的复杂程度会影响模型的泛化能力。如上图所示,训练的数据集主要基于真实的猫狗形象,因此对于虚拟的猫咪形象的学习就会有所不足,想要提高模型的效果就需要不断尝试改善数据集。
2.2 AI项目:MNIST手写体数字识别
MNIST手写体数字识别是最为经典的机器学习案例之一,通过浦育平台,可以简单体验该案例中模型训练与推理的过程。
点击项目,输入关键词搜索,可以找到由官方提供的手写体数字识别的项目。
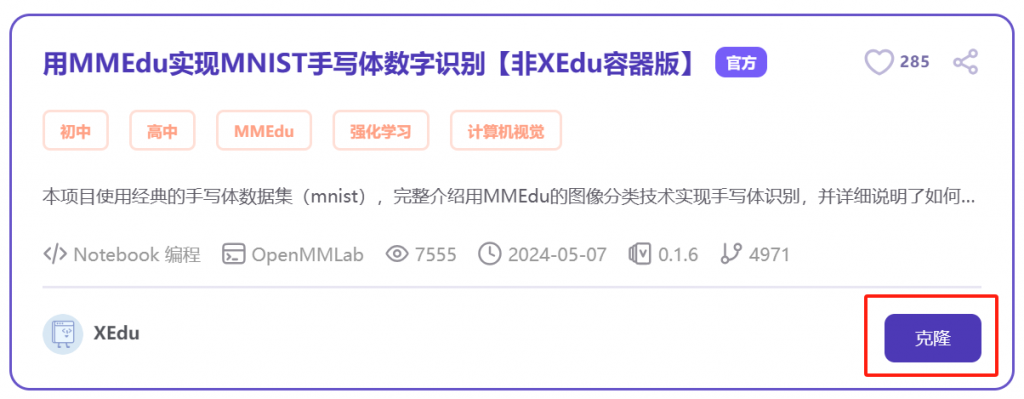
如上图,点击克隆,将项目克隆至我的项目,并进入项目。
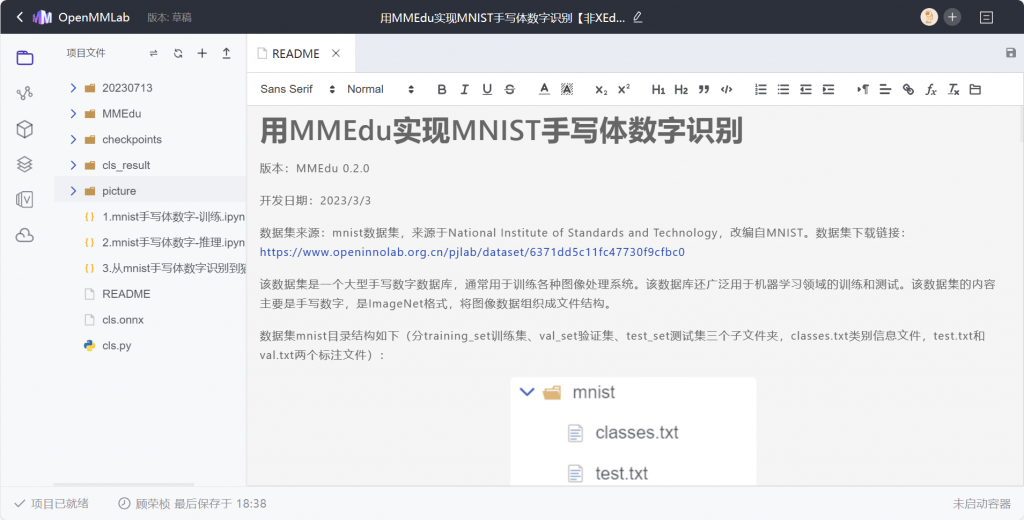
进入项目后的界面如上图所示。
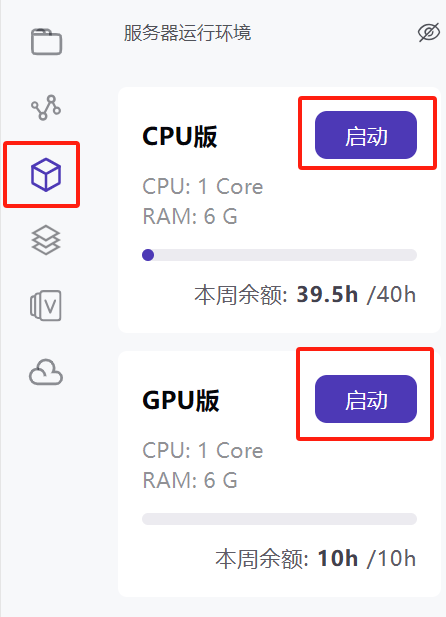
想要在网页端完成模型训练与推理首先要设置服务器运行环境,选择服务器运行环境,选择CPU版或GPU版中的一个点击启动,GPU在模型训练时的速度会更快,可以分别体验两类服务器的训练速度,感受算力对模型训练的影响。
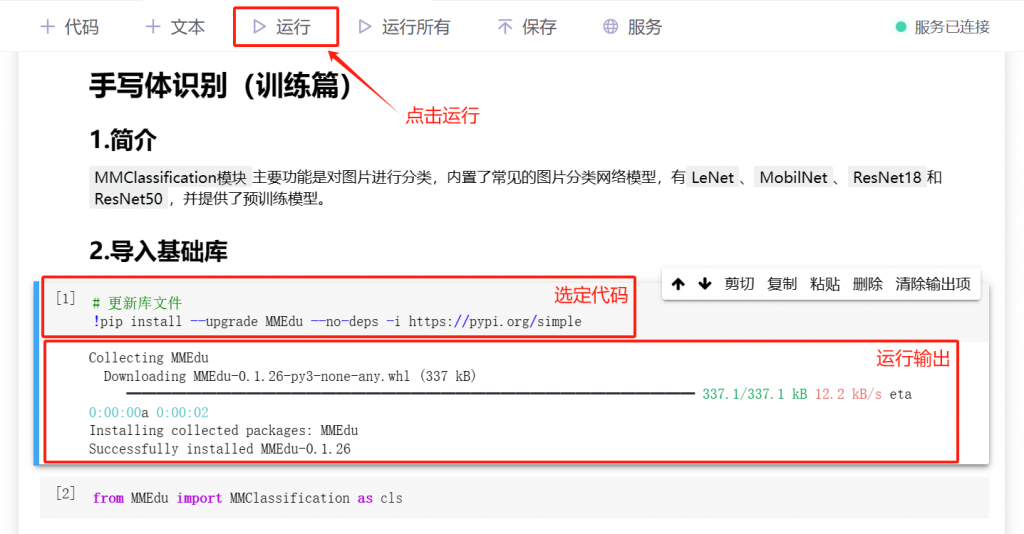
选定服务器运行环境后点击“1.mnist手写体数字-训练.ipynb”文件。选中代码后点击运行即可运行选中的代码块,运行时会输出运行相关信息,代码块前*变成数字时运行结束。项目中对每个代码块的作用都有详细的说明,只要按照说明逐一运行代码即可完成模型训练。
对代码的具体含义将不再赘述,请按照项目内的文本提示,至上而下依次运行所有代码块,完成手写体数字识别模型的训练。

完成模型训练后,如上图所示点击“2.mnist手写体数字-推理.ipynb”文件体验模型训练的结果。
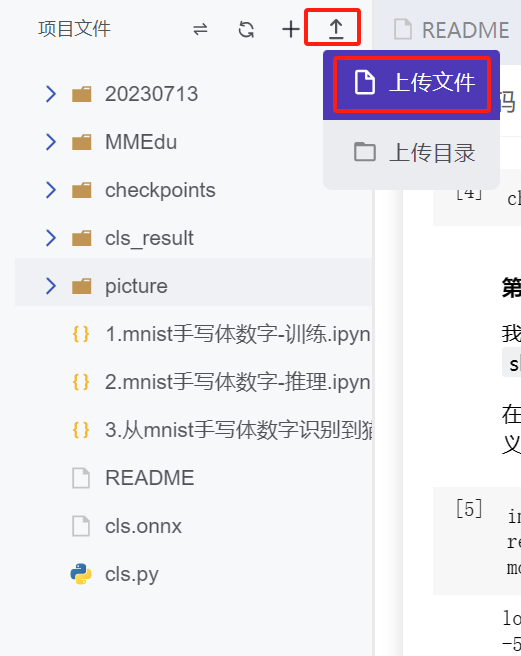
通过将本地图片上传至平台,可以尝试用训练好的模型推理本地图片中的数字。如上图所示,上传图片的方式为:点击列表右上角>点击上传文件。
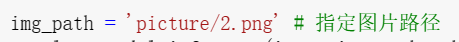
如上图,右键图片会出现复制相对路径选项,复制相对路径至img_path即可按文本提示对图片进行推理。
在本项目的使用过程中,会涉及到学习率、训练轮次等基础的模型训练的概念。在这部分的学习内容中,可以简单了解到数据、算法、算力以及模型等概念。在完成本项目的学习之后也可以尝试体验浦育平台的其他项目,进一步了解想要了解的人工智能相关内容。
3. XEdu与EasyTrain
XEdu的全名为OpenXLabEdu,是基于OpenXLab的教育版,也是为中小学AI教育设计的一套完整的学习工具。OpenXLab是上海人工智能实验室开源的AI工具集合。
XEdu核心工具为深度学习工具库XEduHub、计算机视觉库MMEdu,加上神经网络库BaseNN和传统机器学习库BaseML,支持中小学可能涉及到AI技术所有领域。本节将介绍如何使用EasyDl系列工具中的EasyTrain完成传统机器学习的模型训练。
3.1 XEdu的下载与安装
在OpenXLabEdu帮助文档中详细介绍了XEdu的下载方式,包括一键安装包与pip安装,这里建议使用pip安装的方式安装至新建的环境当中。教程链接如下:XEdu的安装和下载 — OpenXLabEdu 文档
本文将不再赘述XEdu安装的具体流程,如有任何疑问请随时询问助教。
3.2 EasyTrain的使用
首先请打开Anaconda prompt,可在“开始”菜单栏处找到。

打开后输入如下指令并回车运行,环境名为之前安装XEdu的对应环境。
| 1 | activate 环境名 |
进入对应环境后输入如下指令并回车运行。
| 1 | EasyTrain |
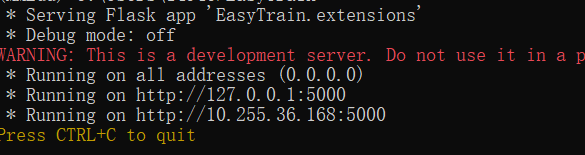
运行后输出如下图所示,复制链接(http://127.0.0.1:5000)在浏览器中打开。
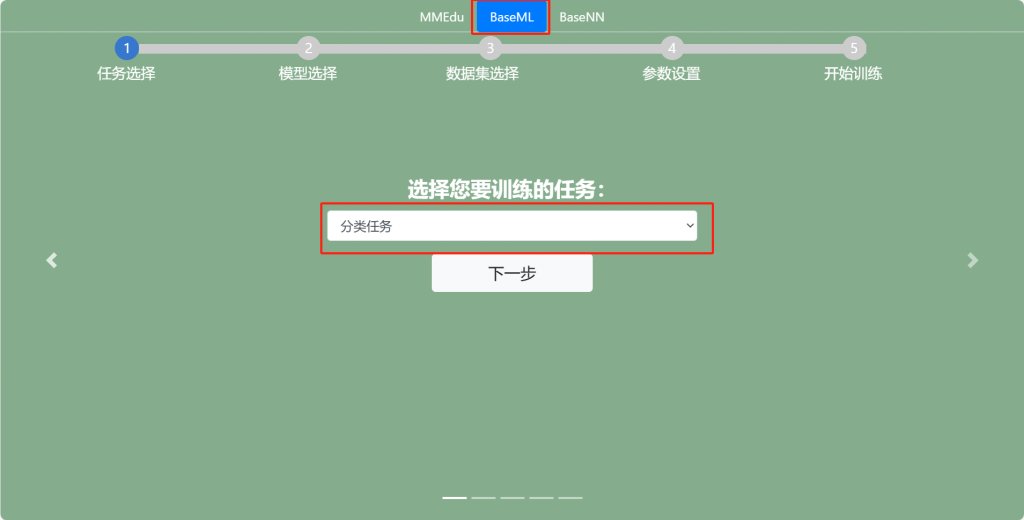
在页面中选择BaseML并选择分类任务,确定后,点击下一步。
模型选择部分不做要求,可自行选择任意一个模型,并点击下一步。
数据集将使用Iris数据集,可自行下载(详见下方网盘链接)。Iris数据集是常用的分类实验数据集,iris以鸢尾花的特征作为数据来源,可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
链接:https://pan.baidu.com/s/1MFAuqfRbKERyNe6J3i0qsg?pwd=2024
提取码:2024
注意:数据集需要下载至指定的文件夹中。网页会读取datasets文件夹之下数据集,而datasets的位置可以看到Anaconda Prompt的运行地址。

以上图为例,数据集需要放在C:\Users\14946\datasets地址下,如下图所示为正确放置数据集后显示的地址信息。
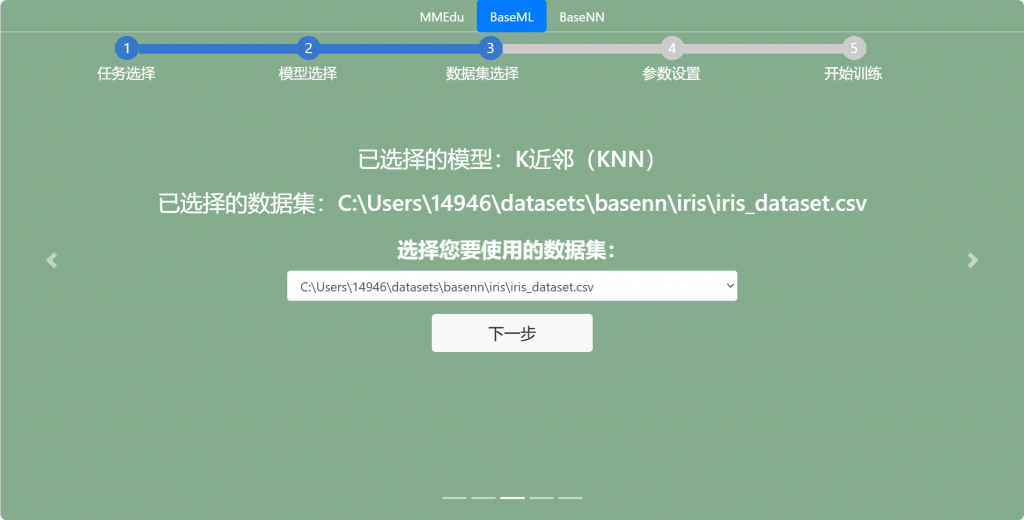
继续点击下一步,参数设置处在数据验证策略部分输入acc,其他保持默认,点击生成代码。
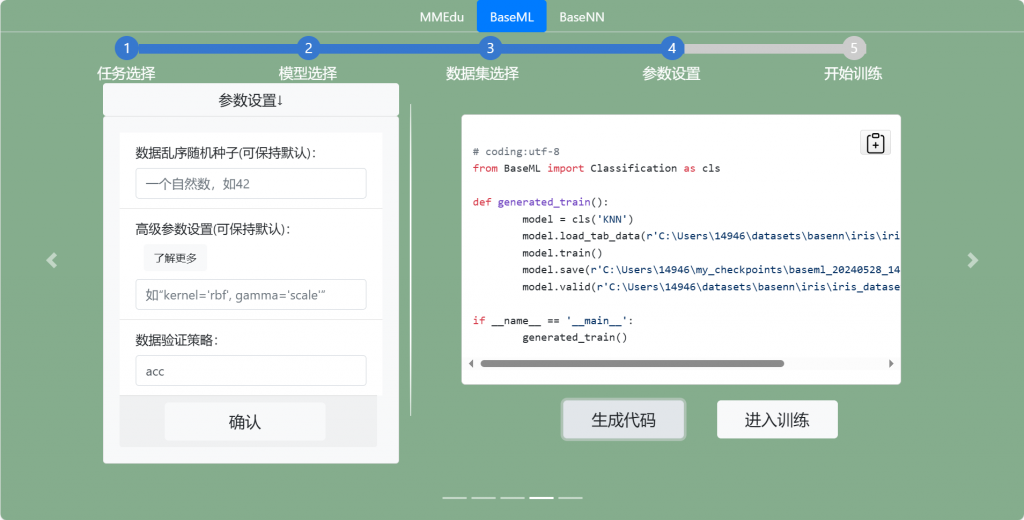
点击“进入训练”并点击“开始训练”。若在与datasets同一目录下的my_checkpoints中找到相应的pkl文件则说明成功完成模型训练。若未能找到pkl则需要手动运行代码指令。

回到参数设置页面,复制生成的代码,并粘贴py文件中,并用VScode运行该文件。
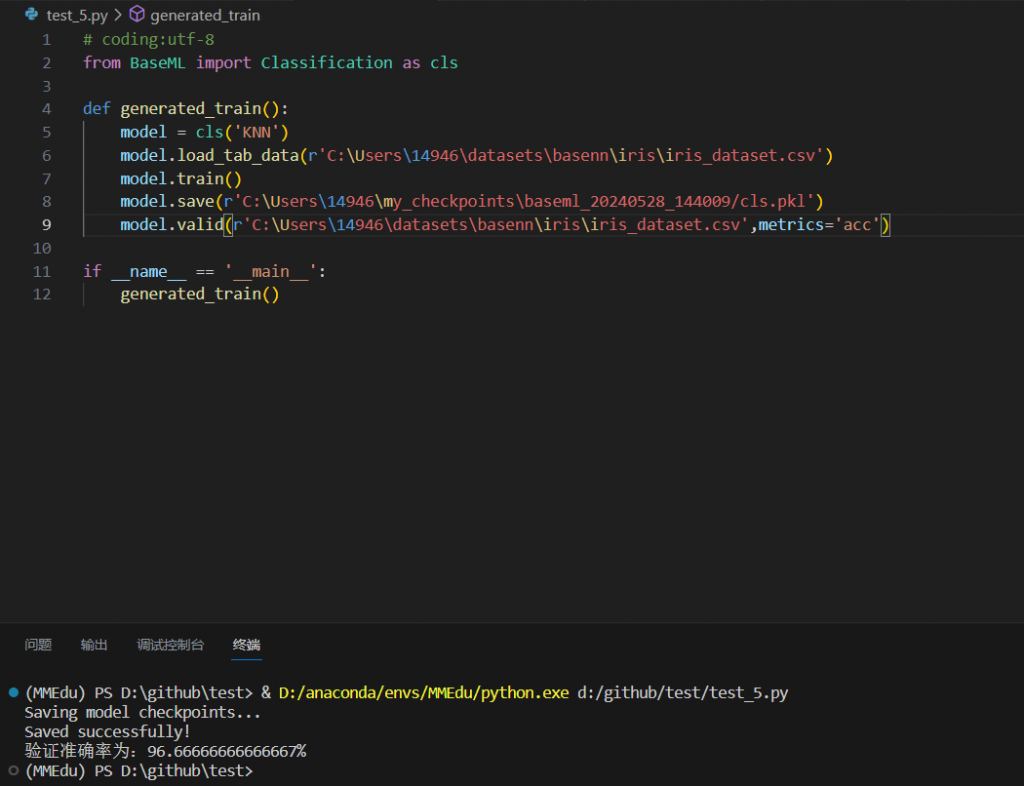
完成运行后可在my_checkpoints中找到对应的pkl文件。
在EasyTrain的“开始训练”页面中已经提供了一串代码用于验证模型效果,如下所示,按要求修改文件路径后,即可验证模型效果。
| 1 | from BaseML import Classification as cls # 导入库文件 |
| 2 | model = cls(‘KNN’) # 这里应该和训练是选择的任务和模型保持一致,任务分别是cls、reg和clt,模型有很多可选 |
| 3 | model.load(r’pkl文件路径’) # 这个文件需要修改为训练完成之后的文件路径 |
| 4 | y=model.inference([[5.1,3.5,1.4,0.2]]) # 输入一组新数据,利用模型进行推理,得到结果 |
| 5 | print(y) # 最简单的查看结果的方式,就是打印结果 |
通过修改第四行的数据,即花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性的值,可以让模型推理鸢尾花的种类。
4. TensorFlow Playground与Python工具(选做)
在之前浦育平台的使用过程中,我们基本完成了对人工智能模型的整个制作过程的学习,但对具体的模型以及算法还未曾深入探究,接下来所介绍的平台将帮助大家了解深度学习以及神经网络。
4.1 TensorFlow Playground(https://playground.tensorflow.org/)
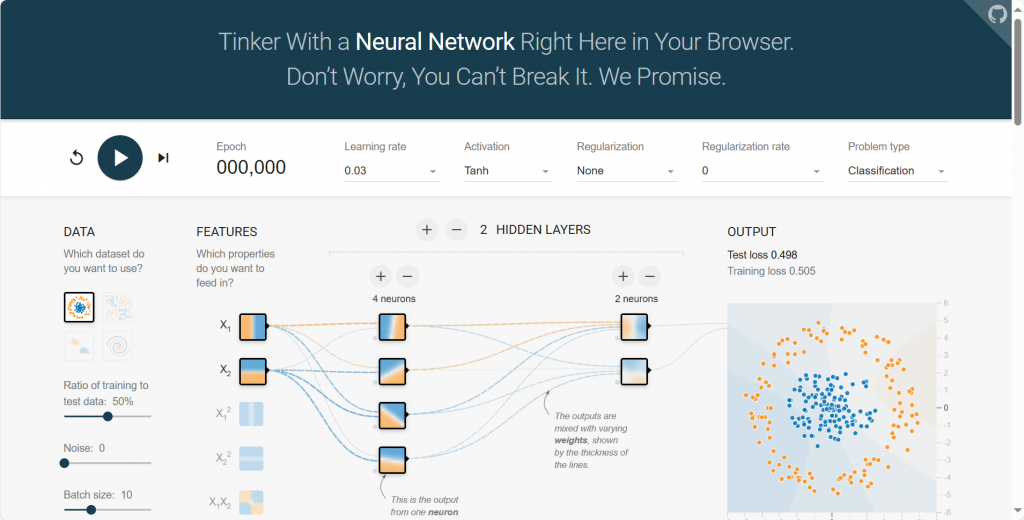
TensorFlow Playground是一个交互式平台,允许用户在简化的环境中可视化和实验神经网络。这个工具特别适用于教育目的,因为它可以帮助学生理解不同的神经网络配置、激活函数和其他参数如何影响学习过程和在各种数据集上的表现。
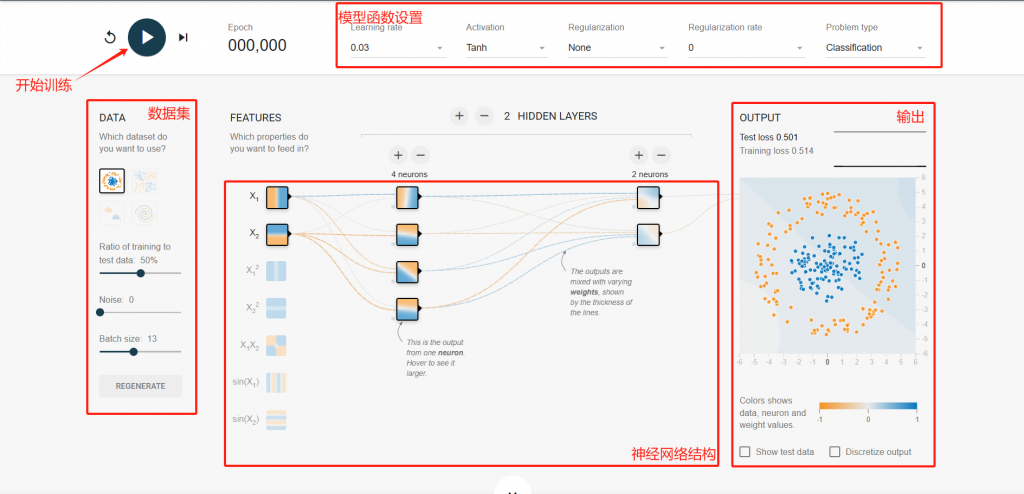
该平台的内容较为丰富,如果想要了解每个选项的含义,可以自行搜索了解,本文只简单介绍该平台的使用方法。左侧的参数是设置数据集,该数据是简单的二维数据,每个点代表一个数据,可以调整参数改变数据集;中间为神经网络的结构,通过加减可以调整神经网络的层数以及每层的神经元数量;上方为模型的参数与函数设置,可以调整模型的学习率、激活函数等数值;右侧为模型输出,点击开始后可以看到模型训练的变化。
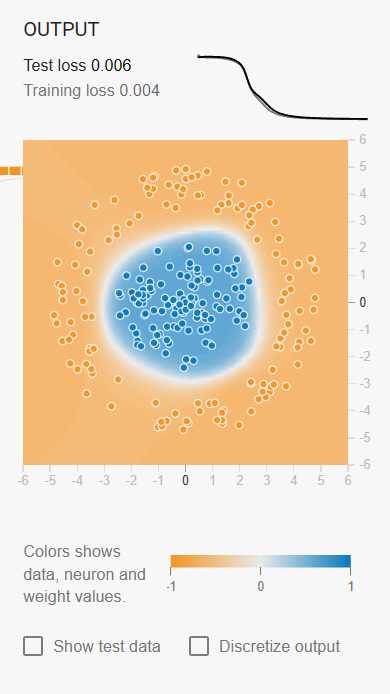
如图所示,开始模型训练后,输出区域将会输出模型对整个坐标图的划分,图中将所有蓝色的点划分在蓝色区域,而所有的橙色点都在橙色区域,可见模型训练效果较好。
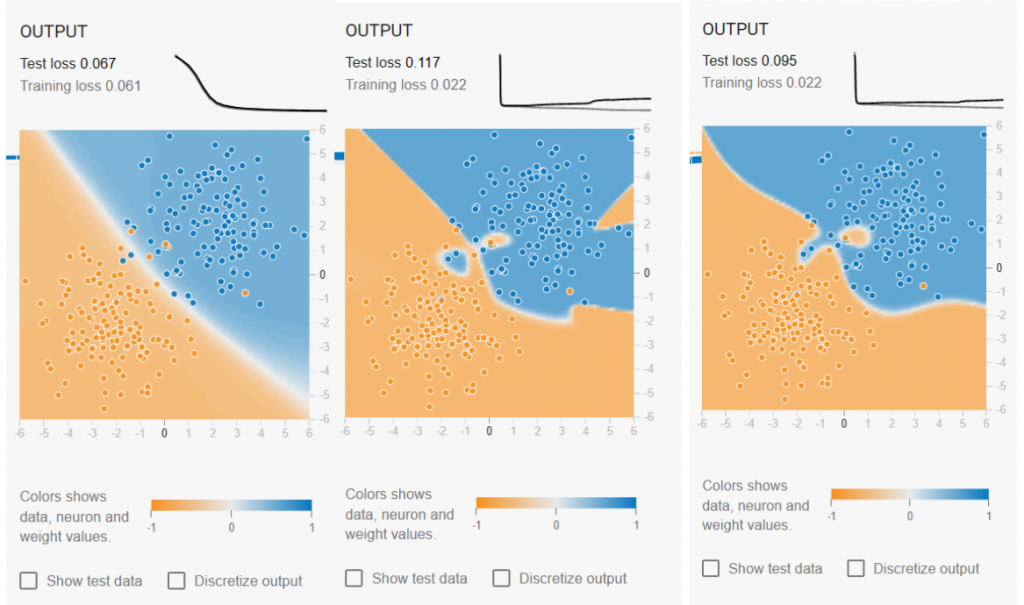
对于更为复杂的数据,可以明显看到模型在训练的过程中效果逐渐变好。中间的图与右侧的图所用神经网络结构不一样,可以看到不同结构的神经网络训练出的模型结果也不同。
TensorFlow Playground的功能非常丰富,感兴趣可以自行探索该平台的使用方法。神经网络所涉及的专业名词较多,难免需要面对大量的理论知识,如果有意进一步深入学习神经网络,可以结合此平台可视化的体验与ChatGPT等工具的名词讲解进行学习。
4.2 Python工具:图片爬取工具
人工智能的学习过程当中难免需要使用到部分Python程序,Python有许多丰富的第三方库可以帮助我们完成作品制作等任务,同时在Github有许多代码可以直接下载使用。本文将简单介绍如何在Github获取图片爬取工具帮助我们搜集图片、制作数据集。
GitHub(https://github.com/)是一个基于 Git 的版本控制和代码托管平台,广泛用于软件开发和协作。
本次我们需要使用的是Github上的一个图片爬取代码。
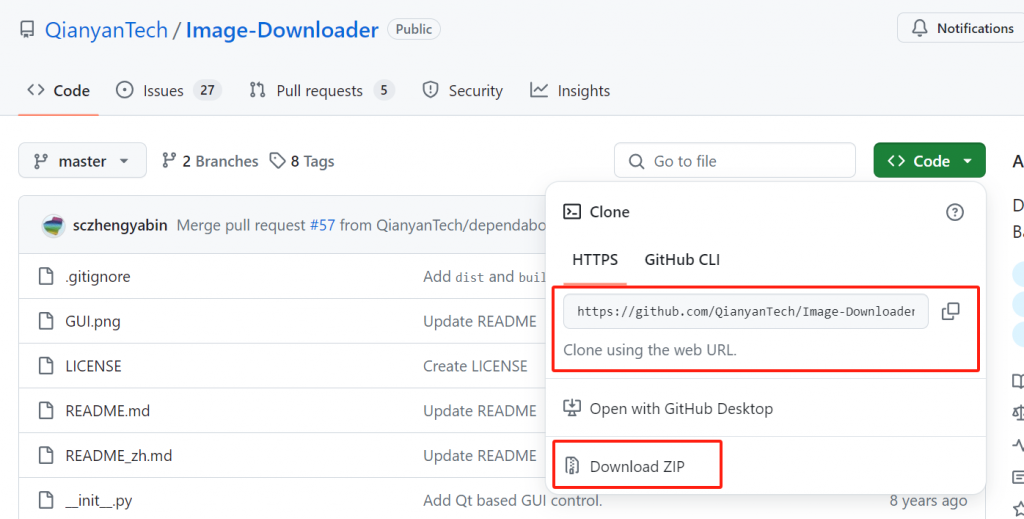
在Github中我们可以通过复制URL用git指令获取代码,也可以直接下载ZIP压缩包。推荐使用git指令下载,具体使用方法可自行搜索学习,本次所要用到的工具可直接下载使用(详见下方网盘链接)。
链接:https://pan.baidu.com/s/122qSkT44LV1NqUCPfLUlLQ?pwd=2024
提取码:2024
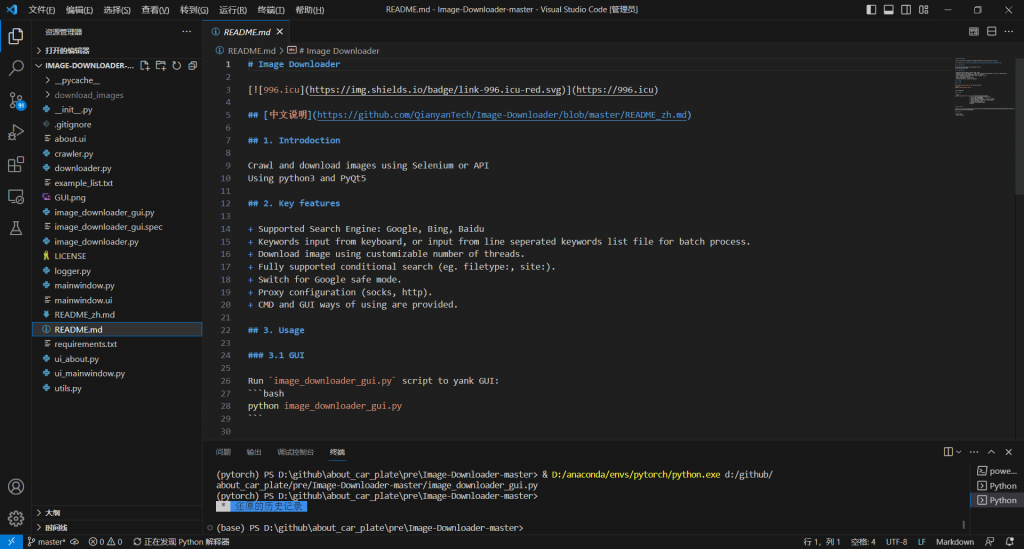
下载完代码文件后,在VScode中选择文件>打开文件夹,选择相应的文件夹(若以压缩包形式下载记得先进行解压)。

打开“image_downloader_gui.py”文件,选择终端>新建终端,界面下方出现如图所示界面,注意所在环境是否为之前创建的虚拟环境,若不是注意切换。
在终端界面中输入以下指令并回车:
| 1 | pip install -r requirements.txt |
该指令用于安装第三方库支持程序运行。耐心等待库下载完成。
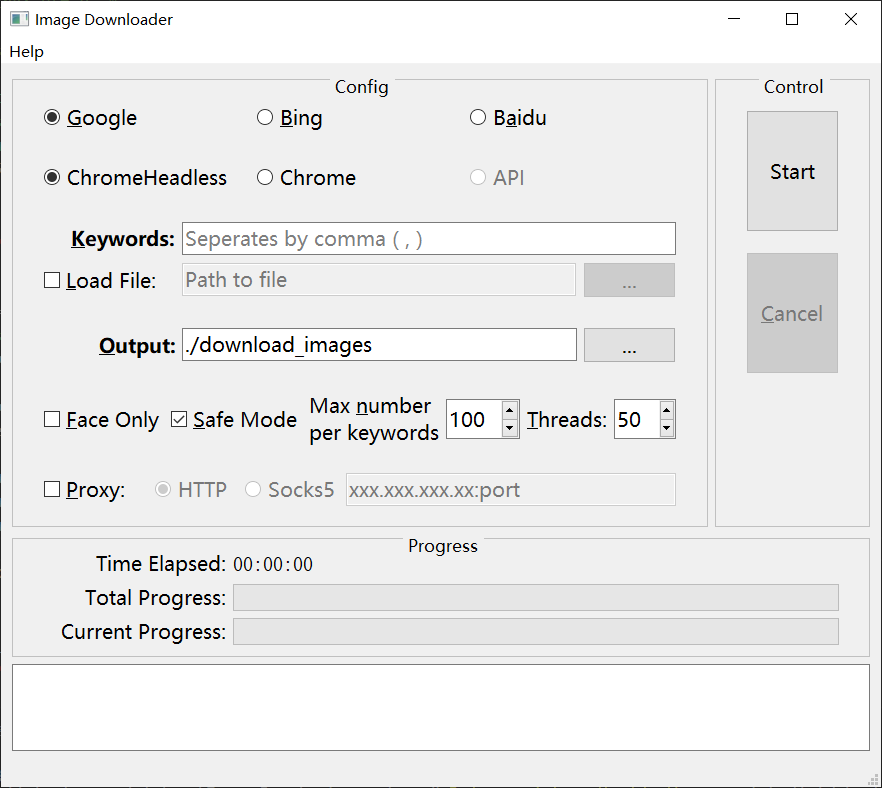
成功运行后将会出现如图所示界面,选择Baidu,API。Keywords输入图片关键词,Max number为每个关键词下载多少张图片,设置完以上内容后,按“Start”即可开始下载图片。
PS:本章节只是简单介绍了一种python代码工具,还有更为丰富的内容欢迎大家自行探索!
Pingback:【线上营】学习任务清单与提交说明 – 科创研学社
Pingback:【营员须知】线上营学习导读 – 科创研学社